Cet article est aussi disponible en français.
Als code-genererend hulpmiddel voor softwareontwikkelaars domineert Github Copilot vandaag de markt. Dat zal wellicht nog wel even aanhouden, zeker nu de tool ook wordt uitgebreid met chatfunctionaliteit à la ChatGPT. Als eigendom van Microsoft, geniet Github van een directe lijn met OpenAI en zo kan het als eerste meegenieten van de voortrekkersrol die dat bedrijf blijft spelen inzake de ontwikkeling van Large Language Models (LLMs).
Men zou haast vergeten dat er ook andere mogelijkheden zijn. Het eerste grootschalige alternatief dat van de grond af open-source was opgebouwd, inclusief open trainingsdata, is StarCoder, waar sinds kort ook een versie 2 van is uitgekomen. Het wordt ontwikkeld onder het BigCode initiatief van ServiceNow en HuggingFace. De bijhorende paper geeft een fascinerende inkijk in de opbouw van een taalmodel voor het genereren van code. Kort na StarCoder verschenen WizardCoder, CodeLLama, DeepSeekCoder en nog enkele anderen ten tonele – niet allemaal met een open dataset erachter, maar wel vrij toegankelijk en herbruikbaar via HuggingFace.
Ondertussen is er voldoende tooling beschikbaar om deze modellen gemakkelijker op een eigen machine te draaien. “Your Own Personal Coding Assistant”, self-hosted en volledig privaat, is vandaag haalbare kaart. We hebben daarvoor nodig: voldoende krachtige hardware, een LLM toegespitst op code completion taken of op conversaties over code, en een plugin voor de IDE. LLM en IDE plugin spreken met elkaar via een API, die al dan niet compatibel kan zijn met die van OpenAI – wat desgewenst toelaat gemakkelijk te wisselen tussen commerciële (OpenAI) en open source modellen.
IDE plugins
Een plugin installeren is op zich gemakkelijk. Github Copilot bestaat al langer als plugin voor VSCode en vandaag ook voor IntelliJ IDEA – al bevat de IntelliJ versie op moment van schrijven nog wat minder functionaliteit.
Onder de open-source alternatieven hoort Continue momenteel waarschijnlijk bij de top. Er zijn er andere – Huggingface zelf heeft bijvoorbeeld llm-vscode ontwikkeld – en ongetwijfeld zullen er nog bijkomen. Net zoals Github Copilot bestaat Continue ook als plugin voor VSCode of IntelliJ. Het kan zowel gebruikmaken van commerciële cloud-based generatoren (waaronder GPT-4) als van zelf gehoste open-source oplossingen. Die hoeven niet noodzakelijk de OpenAI API na te volgen, en er is veel customizatie mogelijk.
Het blijft belangrijk om tijd te investeren om met de plugin te leren werken. De documentatie van Continue is een goed startpunt. Voor elke server en elke LLM kunnen er andere configuratieopties zijn die ingesteld moeten worden, en misschien wil je custom aanpassingen maken aan de achterliggende prompt. Daarnaast is het nodig om te weten hoe de plugin geactiveerd en gedeactiveerd kan worden in de IDE, en welke shortcuts en commando’s er bestaan. YouTube kan een goed startpunt zijn om tutorials en voorbeelden van andere gebruikers te vinden.
Een LLM op je laptop
Vooral onder impuls van het open-source project llama.cpp, zijn er het afgelopen jaar enorme inspanningen gebeurd om LLMs ook inzetbaar te maken op gewone consumentenhardware. Een peperdure GPU is niet meer noodzakelijk, al gaat het met GPU wel nog steeds sneller. In grote lijnen laat llama.cpp toe om een model te herverpakken in het GGUF formaat (GPT-Generated Unified Format). Daarbij worden zoveel mogelijk optimalisaties toegepast:
- gebruik van efficiënte CPU-instructiesets zoals AVX-512 – het spreekt voor zich dat de hardware waarop het model later moet draaien, deze instructiesets ook moet ondersteunen,
- gebruik van sterk geoptimaliseerde high-performance libraries voor de achterliggende berekeningen, zoals openBLAS of Apples Accelerate en Metal,
- het kwantiseren van het model, door het reduceren van de precisie van de gewichten in de lagen van de neurale netwerken. De 16-bit of 32-bit (komma)getallen uit het originele model worden daarbij omgezet naar gehele getallen (integers) van 8-bit, zelfs 6-bit of 4-bit. Dit bespaart geheugen en versnelt de berekeningen, ten koste van een relatief klein kwaliteitsverlies.
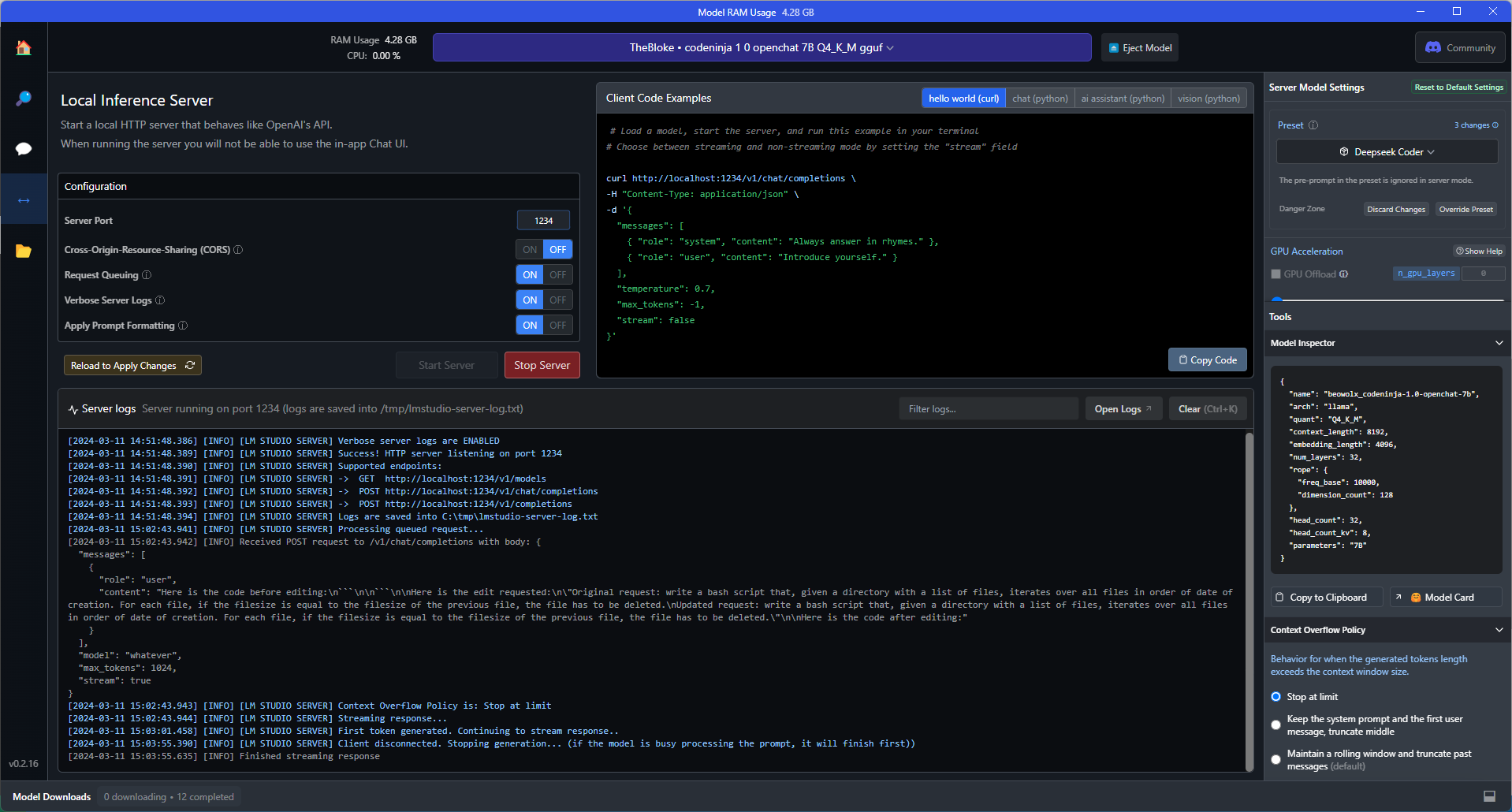
Lokaal een LLM hosten kan met tools zoals LM Studio. Die geven je de mogelijkheid om verschillende modellen te downloaden in GGUF formaat. Een apart tabblad in de applicatie laat toe om een HTTP Inference server rond een gedownload en ingeladen model op te starten, die de API van OpenAI simuleert. Eens deze opgezet is, bijvoorbeeld op poort 1234, is het model aanspreekbaar via een call naar http://localhost:1234/v1/chat/completions .
Dit instellen in de Continue plugin gebeurt door de LLM toe te voegen aan het bestand .continue/config.json , volgens deze instructies en volgens de richtlijnen voor LM Studio als model provider. Daarbij kan je de titel en het model aanpassen naar eigen goeddunken, en hoef je enkel nog de lijn "apiBase":"http://127.0.0.1:1234/v1" toe te voegen. In de plugin zal je dit dan als nieuwe keuzemogelijkheid zien verschijnen, en kan je ermee aan de slag.
Intermezzo: over hardware
Het beheer van GPU’s is al geen pretje voor 1 developer aan 1 machine. Incompatibiliteitsproblemen tussen verschillende versies van allerlei software libraries en GPU-drivers kunnen dagen duren om op te lossen. Het marktaanbod van GPUs voor datacenters, gedomineerd door nVIDIA in een monopoliepositie, is onnoemelijk duur. Daarbij komt nog de kost van het opbouwen van de heel gespecialiseerde kennis die nodig is om die systemen draaiende te houden. Eender wat je kiest van hardware is over 4 jaar waarschijnlijk al helemaal verouderd. Er wordt hard gewerkt aan nieuwe hardware, specifiek gemaakt om het soort berekeningen van AI-modellen te versnellen – Google kwam eerder al met de TPU, maar andere fabrikanten zetten nu ook hard in op NPUs (Neural Processing Units), en sommigen durven directe concurrentie aan met nVIDIA.
Als je geen tijd hebt om te knoeien met GPU-drivers en niet de ambitie hebt om zelf modellen te trainen, dan is de mogelijkheid om ze te gebruiken op een gewone CPU meer dan welkom. Uiteraard ben je dan wel beperkt tot die LLMs of AI-modellen waarvan de grootte dat ook toelaat. Typische LLMs voor “thuisgebruik” hebben 3, 7 of 13 miljard parameters; grotere modellen worden agressief gekwantiseerd om schijfruimte en geheugen te besparen. Ze gaan vandaag nog niet kunnen tippen aan de kwaliteit van GPT-4, maar er bestaan gelukkig leaderboards om te helpen een keuze te maken – voor open LLMs in het algemeen, specifiek met (doorvoer)snelheidsbenchmarks, of voor code-genererende LLMs in het bijzonder.
Hoe groter de LLMs, hoe kwaliteitsvoller het resultaat (meestal), maar ook hoe meer geheugen en rekenkracht vereist is. Een LLM moet liefst volledig in het geheugen ingeladen kunnen worden, dus 16GB RAM is geen luxe – meer is beter, zeker als je een IDE op dezelfde machine wil draaien. Om een antwoord te kunnen te geven, moet het volledige model vaak meermaals doorlopen worden. De bottleneck wordt bijgevolg vaak gevormd door de bandbreedte tussen CPU en RAM. CPUs met een grote interne cache lijken een streepje voor te hebben (zie ook AI-specifieke benchmarks [1,2] van Anandtech). Bij de keuze van de rest van de hardware moet geheugenbandbreedte zeker meespelen. Ook wie een GPU zou willen kiezen, kijkt misschien liever naar die bandbreedte dan naar het aantal cores. Tot slot is het in gevirtualiseerde omgevingen (een VM, een VPS) belangrijk dat de virtuele CPU dezelfde geavanceerde instructiesets, zoals AVX-512, ondersteunt.
Een LLM op je server
Als je elders een krachtigere machine hebt, kan het de moeite waard zijn om de LLM daarop te draaien. ollama is waarschijnlijk de populairste tool om zonder veel poespas modellen te hosten op Mac of Linux, sinds kort ook Windows. LocalAI is echter een zeker zo interessante optie uit de lijst van mogelijke LLM providers voor Continue, want het biedt Docker containers aan, met of zonder GPU ondersteuning. Op een Linux machine die is uitgerust met Docker, is een oneliner in de terminal voldoende om het open-source CodeLlama model te downloaden en te beginnen hosten op poort 1234:
docker run -ti -p 1234:8080 localai/localai:v2.7.0-ffmpeg-core codellama-7b-gguf De opstart ervan duurt echter even, want het model wordt in de container gedownload. Interessanter is het om zelf een reeks modellen in een lokale map te bewaren, en daaromheen een API te zetten middels een LocalAI container. Ook voor die aanpak zijn relatief eenvoudige instructies beschikbaar. We kunnen ze bijvoorbeeld toepassen op de DeepSeek LLM van 6.7 miljard parameters, gekwantiseerd op 4 bits. Deze kan rechtstreeks van Huggingface gedownload worden naar de lokale map ./models-gguf met een wget commando van het type:
wget https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/resolve/main/deepseek-coder-6.7b-instruct.Q4_K_M.gguf -O ./models-gguf/deepseek-6.7b-instruct-Q4Een API starten rondom de modellen in die map op poort 8001 (je kan ook meerdere modellen in dezelfde map zetten en ze tegelijk hosten), kan dan met het volgende commando. Voeg eventueel -d toe om het in de achtergrond te laten lopen, en voel je vrij om met de parameters context-size en threads te experimenteren in functie van hoe krachtig je server is:
docker run -p 8001:8080 -v $PWD/models-gguf:/models -ti --rm quay.io/go-skynet/local-ai:v2.7.0-ffmpeg-core --models-path /models --context-size 1600 --threads 16Voorbeeld
We kunnen nu verschillende LLMs voor code met elkaar vergelijken. We houden het hier louter anekdotisch, en nemen als eenvoudig voorbeeld het schrijven van een bash shellscript. We vertrekken van het volgende probleem: een backup-routine heeft jarenlang een nachtelijke backup genomen van een systeem. Om schijfruimte vrij te maken, willen we alle backups verwijderen die niet verschillen van de vorige. We geven de volgende opdracht, waarbij we de taak zo nauwgezet mogelijk omschrijven voor het beste resultaat: “Write a bash script that, given a directory, iterates over all its files in order of date of creation. For each file, if the filesize is equal to the filesize of the previous file, the file has to be deleted.”
De .continue/config.json file van onze Continue plugin bevat de volgende lijst modellen: eentje op de eigen laptop in LM Studio ingeladen op poort 1234, en twee op een aparte server in het lokaal netwerk, door LocalAI gehost op poort 8001.
{
"title": "myLaptop-LMStudio",
"model": "whatever is loaded in LMstudio",
"apiBase": "http://127.0.0.1:1234/v1",
"completionOptions": {},
"provider": "lmstudio"
},
{
"title": "localAI-mistral",
"model": "mistral-7b-code16kqlora-Q4",
"apiBase": "https://192.168.0.100:8001/v1",
"apiKey": "",
"completionOptions": {},
"provider": "openai"
},
{
"title": "localAI-deepseek",
"model": "deepseek-6.7b-instruct-Q4",
"apiBase": "https://192.168.0.100:8001/v1",
"apiKey": "",
"completionOptions": {},
"provider": "openai"
},Als referentie nemen we ChatGPT, die komt met de volgende (correcte) oplossing. Bovendien wordt ze ook gevolgd door een uitgebreide uitleg over wat de verschillende onderdelen betekenen (hier niet weergegeven):
#!/bin/bash
# Directory containing the files
DIR="/path/to/your/directory"
# Variable to hold the size of the previous file. Initialized to 0.
prev_size=0
# List all files in the directory, sorted by creation date
# Note: '%T@' sorts by creation time, '%p' prints the file's name
# 'sort -n' ensures the list is sorted numerically
# Note that creation time sorting may depend on filesystem and OS support
files=$(find "$DIR" -type f -printf "%T@ %p\n" | sort -n | cut -d ' ' -f 2-)
# Iterate over the sorted list of files
for file in $files; do
# Get current file size
current_size=$(stat -c %s "$file")
# Check if current file size is equal to the previous file's size
if [ "$current_size" -eq "$prev_size" ]; then
# Sizes are equal, delete the current file
echo "Deleting file: $file"
rm "$file"
fi
# Update previous size to current file's size
prev_size=$current_size
doneIn LMStudio laden we het model “CodeNinja 1.0 openchat 7B Q4_K_M” in. Voor het genereren van het antwoord op dezelfde vraag is ruim 1 minuut nodig: 20 seconden wachten tot de eerste letter van het antwoord verschijnt, daarna nog ongeveer 2 seconden per lijn. (Onze laptop is natuurlijk niet superkrachtig: een Core i7-10610U CPU met 32GB RAM). Het volgende komt eruit:
#!/bin/bash
for f in $(ls -t -l --time-style=full /path/to/directory)
do
if [[ $f == "total"* ]]; then
continue;
fi
filename=$(basename "${f% *}")
# Checks whether the file is already deleted. If not, compares it with the previous file:
prev_file=""
while IFS= read -r line; do
if [[ $line == $filename ]]; then
prev_file=$line
break;
fi
done <<<"$(ls -l /path/to/directory | tail -n 2)"
if [[ -z $prev_file || "$f" = "${prev_file}" ]]; then
# If the file is deleted, nothing to do. If not, deletes it:
if [[ -z $prev_file ]] || [[ "$(stat -c %s ${filename})" == "$(stat -c %s ${prev_file})" ]]; then
rm /path/to/directory/$filename
fi
fi
doneHet DeepSeek model van 6.7 miljard parameters laden we in LocalAI op een Debian VM in Proxmox. Aan de VM is ruim voldoende RAM toegekend, en 12 cores van de onderliggende hardware, een AMD Threadripper 3960X processor (24 cores maar geen AVX-512 ondersteuning). Hiermee creëren we aan een snelheid van ongeveer 3 lijnen per seconde het volgende resultaat:
#!/bin/bash
# Check if directory is provided
if [ $# -ne 1 ]; then
echo "Usage: $0 directory"
exit 1
fi
# Check if directory exists
if [ ! -d "$1" ]; then
echo "Directory $1 does not exist"
exit 1
fi
# Change to the directory
cd "$1"
# Get the list of files in order of creation date
files=$(ls -t)
# Initialize previous_size to 0
previous_size=0
# Iterate over the files
for file in $files; do
# Get the size of the file
size=$(stat -c%s "$file")
# If the size is equal to the previous size, delete the file
if [ $size -eq $previous_size ]; then
rm "$file"
echo "Deleted $file"
fi
# Update previous_size
previous_size=$size
doneTot slot kunnen we op dezelfde VM ook het recentere Mistral uitproberen, waarvoor we op goed geluk de versie mistral-7B-code-16K-qlora uitkiezen die door een andere gebruiker lichtjes werd bijgetraind voor code. Deze blijkt zeer snel te kunnen antwoorden, en genereert in ongeveer 2 seconden het volgende compacte resultaat (helaas zonder documentatie, en gebruikmakend van het complexe awk commando):
for file in $(find directory -type f -exec du -sh {} + | sort -h | awk '{print NR ":\t" $1}'); do
size=$(du -sh "$file" | awk '{print $1}')
if [[ $size == $previous_size ]]; then
rm "$file"
fi
previous_size=$size
doneIk laat de diepgaandere vergelijking van deze resultaten graag over als oefening aan de lezer. Als we hieruit nog een laatste les moeten leren, dan is het dat er ook tussen modellen onderling, zelfs al hebben ze dezelfde hoeveelheid parameters en zijn ze voor hetzelfde doel getraind, erg grote verschillen kunnen zijn qua output en stijl!
Conclusie
Aan sneltempo vinden allerlei AI-powered features hun weg naar de IDE. De laatste release notes van Visual Studio Code vermelden naast verschillende CoPilot features bijvoorbeeld ook ondersteuning voor spraakherkenning in meerdere talen. Het is onvermijdelijk dat je daar als developer mee in contact zal komen. Developers die werken met gevoelige data of copyrighted code, zijn terecht argwanend over het feit dat zulke tools hun IDE-inhoud naar een of andere clouddienst van een derde partij versturen, om suggesties te kunnen genereren.
Vooral dankzij het llama.cpp project, is er recent een alternatieve open-source route ontstaan die toelaat zulke coding assistentie met LLMs zelf op te zetten en uit te baten. Kleinere modellen die op consumentenhardware kunnen draaien, leveren momenteel niet dezelfde kwaliteit en snelheid als Github CoPilot of ChatGPT. De komende jaren zullen we echter regelmatig verdere verbeteringen zien verschijnen, dus de ingezette weg oogt alleszins veelbelovend.
______________________
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply