Research blog
-
“Vergeetachtige verzending” voor vertrouwelijk onderzoek naar personen
Geregeld is onderzoek nodig naar verdachte personen. Dit neemt niet weg dat de privacy van deze en andere personen gerespecteerd moet worden. Ook de confidentialiteit van het onderzoek moet gegarandeerd blijven. Dit artikel reikt een waardevolle technologie aan om aan deze vereisten tegemoet te komen. Het spanningsveld Er wordt regelmatig vanuit justitie onderzoek gevoerd naar
-

Conversation design
Spraakassistenten worden meer en meer naar voor geschoven als nieuwe vorm van interactie met computersystemen. Siri, Alexa en Google Assistant strijden om de plaats van geprefereerde virtuele assistent. Ze duiken op in allerlei toestellen: in smartphones, smart speakers, tot zelfs in de auto. Naast Engels en Frans wordt ook het Nederlands meer en meer ondersteund.
-

Cryptografische pseudoniemen snellen de GDPR te hulp
Er worden steeds meer persoonsgegevens verwerkt, die dan ook op een afdoende manier beschermd moeten worden. Vaak volstaan de genomen veiligheidsmaatregelen niet en lezen we in de pers over opnieuw een data breach of over het niet respecteren van de privacy. Cryptografische pseudonimisatie is een relatief weinig gekende technologie die dergelijk misbruik een pak moeilijker
-

Data Quality : mesurer les valeurs rares
Des données, à partir du moment où elles vivent et sont alimentées, souffrent presque systématiquement de problèmes de qualité. Le domaine de la Qualité des données (Data Quality) est vaste, très actif tant dans le monde académique qu’industriel. Il y a bien évidemment des aspects méthodologiques (améliorer les processus pour que les données qui rentrent
-

Anomalies & Transactions Management System (ATMS) : enjeux, concepts, réalisations et travail en cours
Cet article de blog a pour objet d’introduire le concept d’ATMS (Anomalies & Transactions Management System) : après en avoir montré l’importance fondamentale dans le cadre du « back tracking » récemment évoqué dans un article de blog de mai 2018, nous en rappelons les principales références ; nous en évoquons ensuite les concepts généralisables, le ROI, l’originalité ainsi
-

Hergebruik: Enkele Do’s en Don’ts…
Hergebruik: het gebruiken van een bestaand stuk software voor een nieuwe toepassing. Het lijkt een eenvoudig principe, maar er komt meer bij kijken dan je zou denken. Vooral wanneer je effectief een software artefact probeert te hergebruiken, creëer je al snel problemen. In deze blog gaan we wat dieper in op dit ogenschijnlijk simpele productiviteitsprincipe.
-

AI en desinformatie
Het (private) onderzoekslab OpenAI publiceerde kort geleden een van hun laatste resultaten: ze zijn er in geslaagd om relatief realistisch uitziende teksten te genereren van enkele paragrafen lang, gegeven een eerste zin. Ze namen tegelijk de opmerkelijke beslissing hun code en model niet openbaar te maken, omdat die dan te gemakkelijk en te snel te
-

Cognitive Search: l’évolution des moteurs de recherche d’entreprise
« Data is the New Gold » : voici une citation que l’on a maintes fois vue et entendue quand il s’agit de parler de science des données ou d’intelligence artificielle. Ce blog se concentre sur les données non structurées et textuelles et une des nouvelles techniques qui permettent d’extraire « l’or » contenu dans celles-ci. Les entreprises et organisations
-
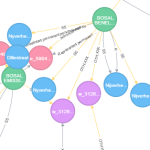
Sept (bonnes) raisons d’utiliser une Graph Database
Ces dernières années, les bases de données orientées graphes (ou Graph DB, présentées dans nos blogs précédents [1, 2]), et plus généralement les bases de données NoSQL, ont énormément gagné en popularité et en visibilité. Pour preuve, Neo4j, le leader actuel du marché des Graph Databases, apparaît depuis 2014 dans le “Magic Quadrant for Operational
-

Facetten van Natural Language Processing – deel 2
Veel aspecten van Natural Language Processing (NLP) steunen op een of andere vorm van classificatie. Als we een tekst automatisch willen analyseren of begrijpen, zal het immers snel nodig zijn om labels aan (groepen van) woorden of zinnen toe te kennen. Op basis van die labels of annotaties kan de analyse verdergezet worden. Classificatie is
Keywords:
analytics Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality development EDA egov Event GIS Information management Machine Learning Managing IT costs methodology Mobile Natural Language Processing Open Source Privacy Productivity Security social software design software engineering standards